Facial Keypoint Detection with Neural Networks
Matthew Hallac
Overview
For this project, I use neural networks to automatically detect key points on faces.
Nose tip detection
For the first part, given a face I try to detect only the tip of the nose. I compressed the images to 80x60 grayscale and used three convolutional layers with kernel size 3x3, with each followed by a max pool and a relu. My number of output channels went from 16 to 20 to 32, and these layers were followed by two fully connected layers from 1280 to 120 to 2, the x and y coordinates of the nose.
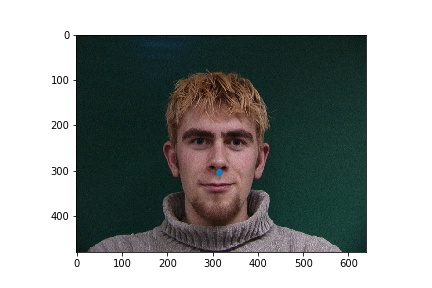
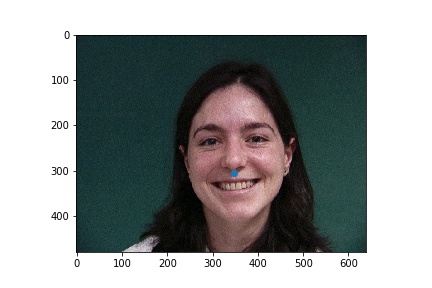
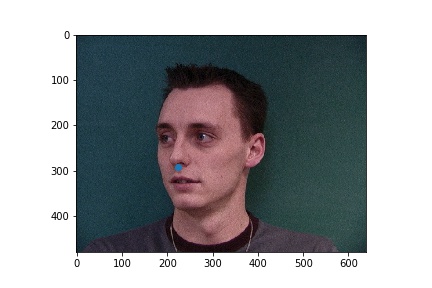
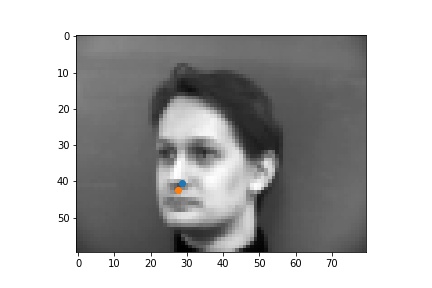
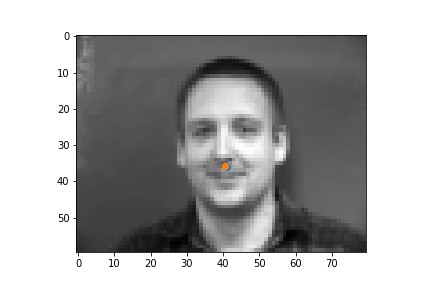
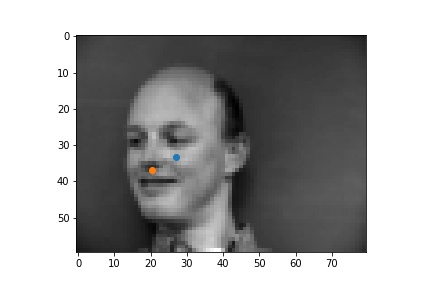
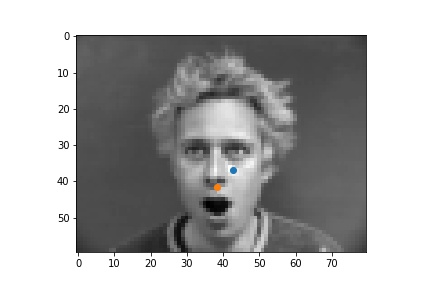
In the failure cases above, the nose was incorrectly identified to be below the eye. This could be due to the low amount of data that was used for training. The failure case on the left identifies the point as closer to the center of the image than it actually is, and that could be due to the face that for this step, data augmentation was not implemented, and when the face is not perfectly centered the network will get it wrong.
Full facial keypoints detection
Now, given a face I try to detect 58 keypoints. I used data augmentation with random rotations and translations and colorjitter.
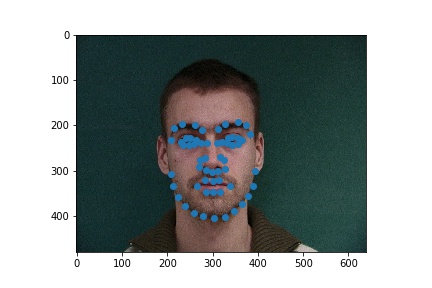
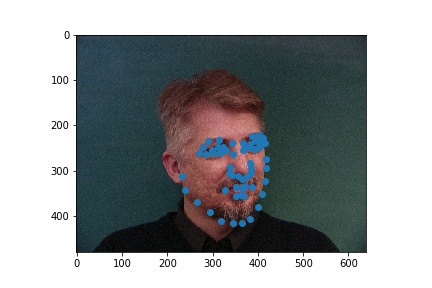
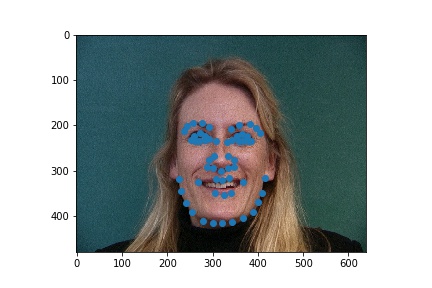

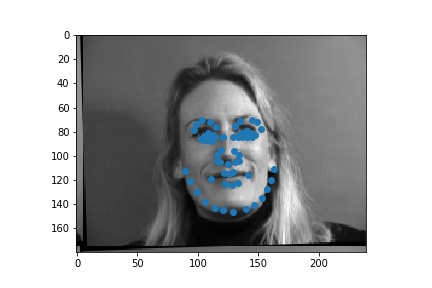
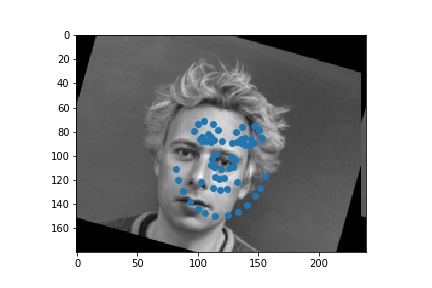
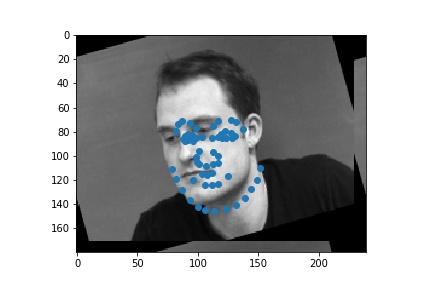


The architecture of my example was as follows:
- Convolution layer from 1 -> 16 channels with a kernel size 3x3, follwed by a relu and a max pool of size 2x2
- Convolution layer from 16 -> 16 channels with a kernel size 3x3, followed by a relu and a max pool of size 2x2
- Convolution layer from 16 -> 32 channels with a kernel size 3x3, followed by a relu and a max pool of size 2x2
- Convolution layer from 32 -> 64 channels with a kernel size 3x3, followed by a relu and a max pool of size 2x2
- Convolution layer from 64 -> 64 channels with a kernel size 3x3, followed by a relu and a max pool of size 2x2
- A fully connected layer from 960 -> 960 channels
- Another fully connected layer from 960 to the output size of 58*2 = 136
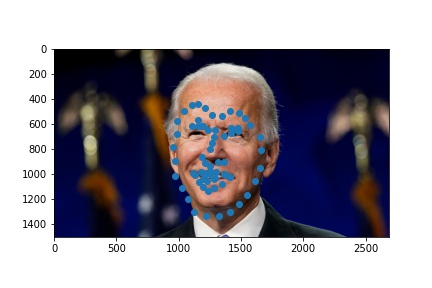
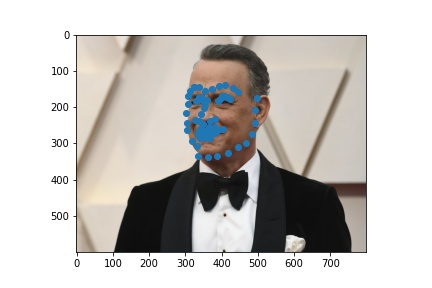
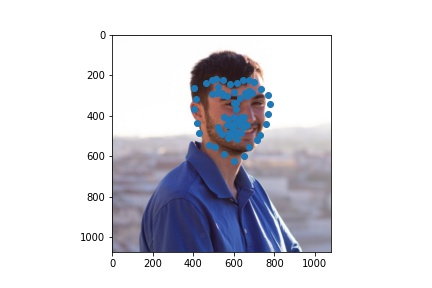
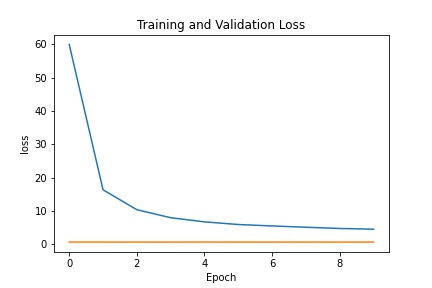
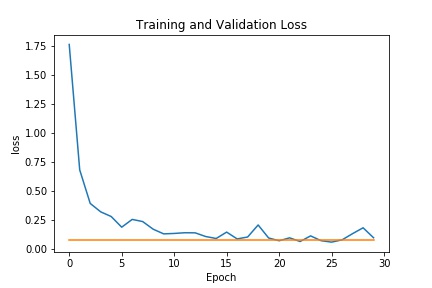
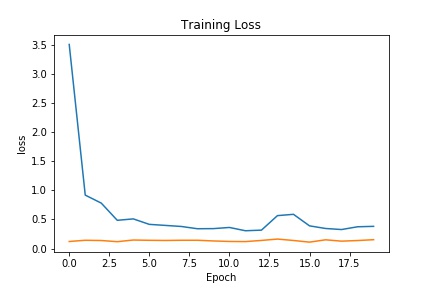
Train with a larger dataset
For the larger dataset, I used the Resnet18 model from pytorch with some modifications. The architecture consisted of the following:
- Convolution from 1 -> 64 with a kernel size of 7x7 and a stride of 2, with a padding of 3
- Batching followed by relu and maxpool
- Layer 1: convolution, batching, relu, convolution, batching repeated twice
- Layer 2: same as layer 1 with a downsample and additional convolution in the middle
- Layers 3-4: Repeats of above
- An average pool, followed by a fully connected layer
Here were my results from the test dataset:

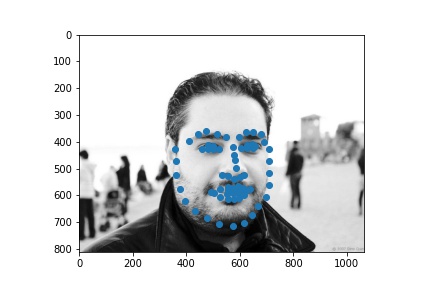
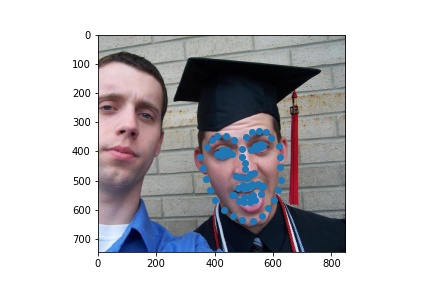
Here are the results on my own images